The AI Vibe Shift: Mapping 5 Years of Public Sentiment
At Redytics, we track user conversations in tech to help teams spot market trends early. No sector moves faster than artificial intelligence. To see how developers and users actually feel about major AI models over time, we tracked user sentiment from mid-2021 to April 2026 (our final data cutoff point).
Using a Bayesian Smoothed Exponential Moving Average (EMA), we analyzed hundreds of thousands of organic discussions across developer forums and tech communities. Here is our breakdown of how public perception has evolved.
The Big Picture: Sentiment Trends Over Time
Below is the full sentiment chart over the last five years. We matched major model releases directly to the sentiment lines to show exactly how new product launches change user perception.
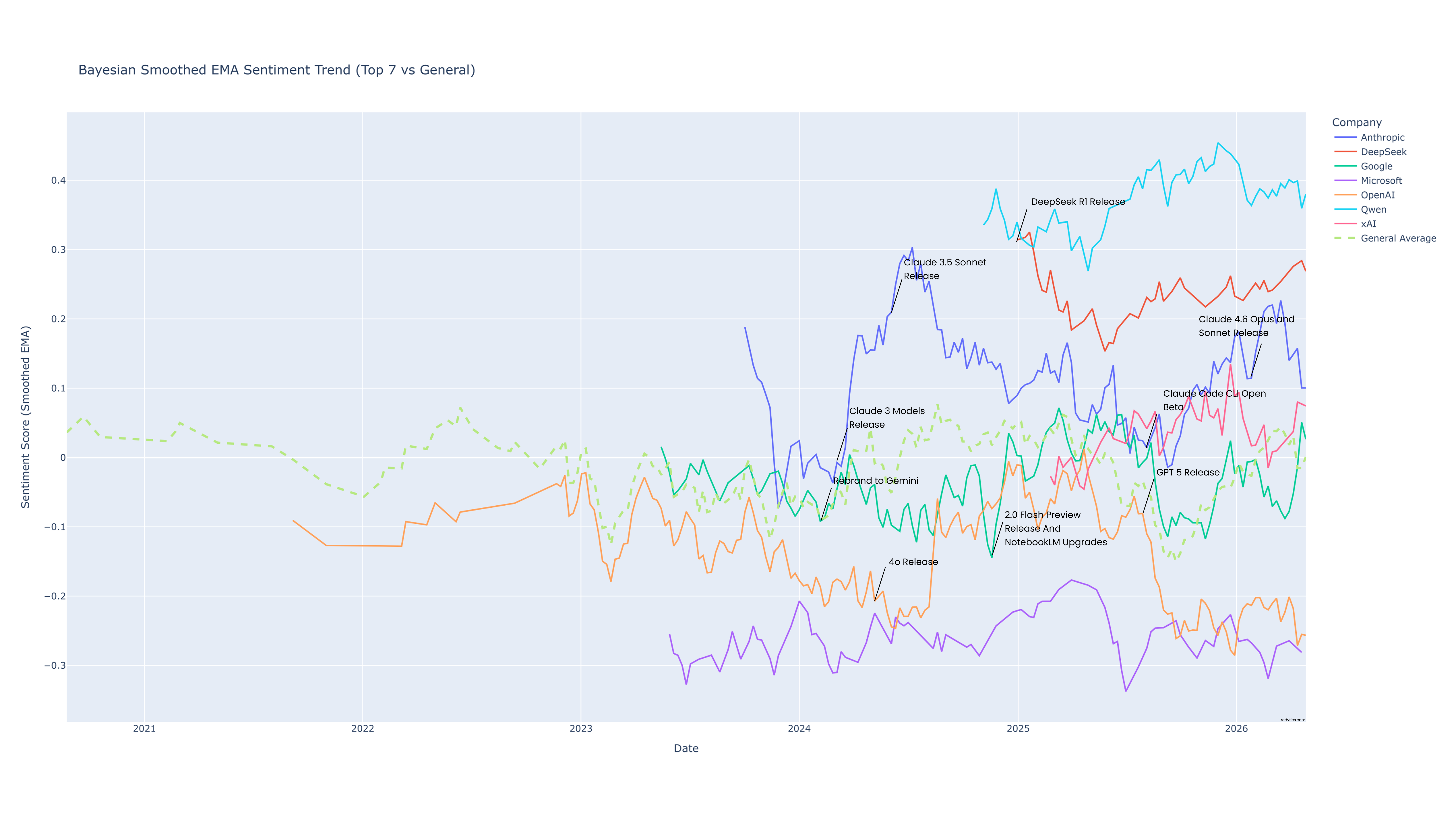
Core Insight: Why Open Models Outperform Consumer Giants
When looking at the chart, a clear gap stands out: Qwen and DeepSeek models hold a huge, steady lead at the top of the spectrum (averaging between +0.2 and +0.45), while models from industry giants like OpenAI (ChatGPT) and Microsoft trend significantly lower (anchoring between -0.1 and -0.3).
To keep the data accurate, our NLP pipeline looked strictly for specific model names (like ChatGPT, Claude, Gemini, Qwen, or DeepSeek) instead of company names, corporate politics, or stock market news. This gives us a pure look at how people feel about the actual product performance:
-
The Utility Win: Open-weights models like Qwen and DeepSeek are heavily favored by technical users. They are open, easy to run locally, and work incredibly well. When developers talk about these specific models, the feedback is overwhelmingly positive because the tools solve real engineering problems without corporate guardrail friction.
-
Product Flaws & Frustrations: The lower scores for Microsoft and OpenAI models come down to real product issues. For Microsoft, users consistently felt that their model implementations simply underperformed and didn't live up to the hype. For OpenAI, it was a mix of comments on initial model performance when LLMs were still quite new and GPT-5 being initially a bit underwhelming.
Key Milestone Case Studies
Our tracking captures immediate sentiment responses to critical product releases:
1. Anthropic's Steady Climb (Claude 3 & 3.5)
Anthropic focused heavily on code quality, and it paid off. The launch of the Claude 3 Model Family in early 2024 started a steady upward trend that peaked right after Claude 3.5 Sonnet dropped. This matches the massive shift where developers switched to Sonnet for daily programming tasks.
2. The GPT-5 Launch Backlash
In late 2025 and early 2026, the highly anticipated GPT-5 Release caused a massive wave of chatter. Right after it dropped, the ChatGPT sentiment line took a sharp, severe plunge deep into negative territory. Our pipeline verified that this wasn't random noise; it was an immediate user backlash against a fundamentally poor product launch. Forums were flooded with comments on bugs, feature lockouts, and disappointing performance.
3. Google's Recovery (Gemini 2.0)
Google spent a long time climbing out of a negative hole. Rebranding to Gemini helped stabilize things, but the real turning point was shipping Gemini 2.0 Flash and the NotebookLM Upgrades in late 2024/early 2025. Users love fast, practical tools, and these releases successfully built back goodwill.
Yearly Breakdown: Thresholds and Missing Data
To see the broader trends across different periods, we grouped the average sentiment by year. For a company's models to show up on this chart, they needed a minimum threshold of at least 100 verified mentions in our dataset for that specific year.
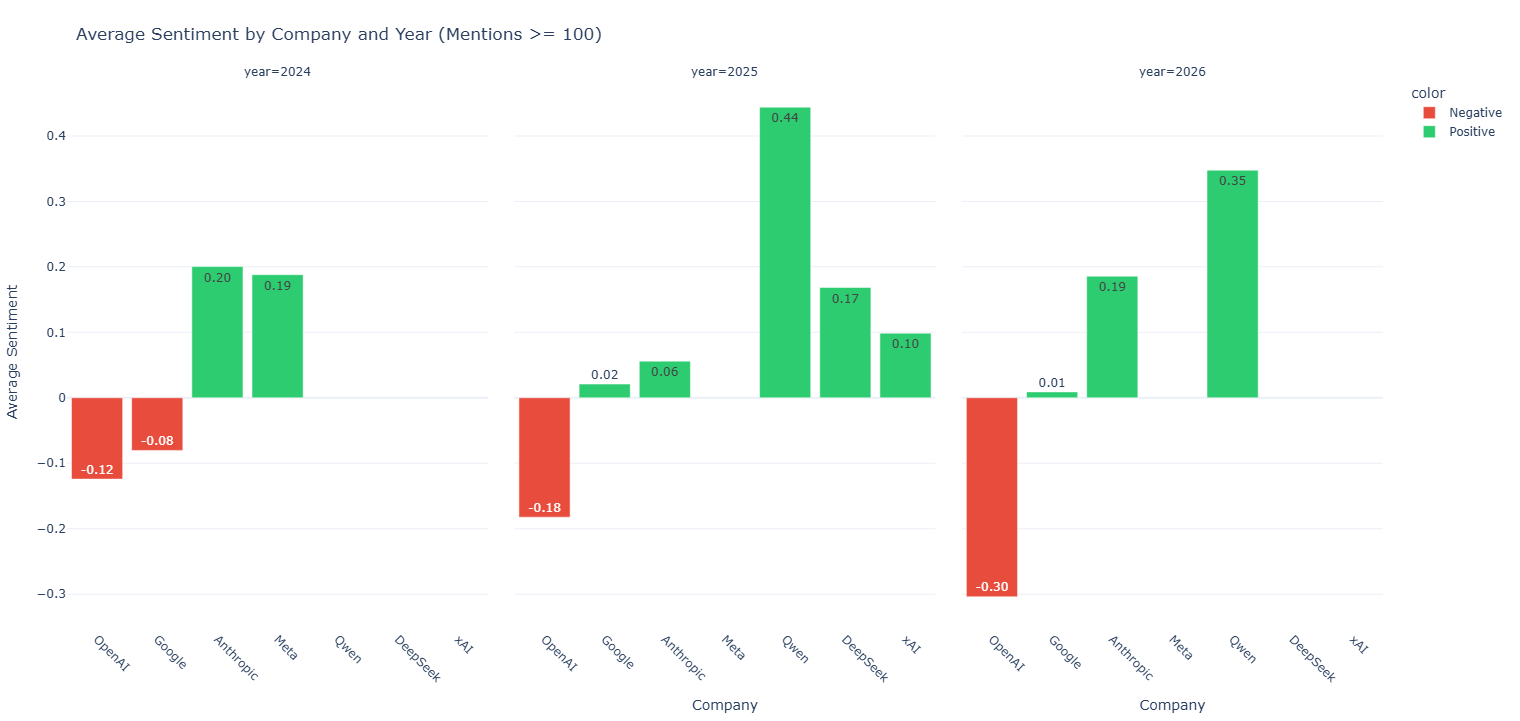
Looking at the yearly data from this perspective reveals two important patterns regarding missing data points:
- The Disappearance of Meta: In 2024, Meta models held a strong positive sentiment score of
+0.19. However, in 2025 and 2026, Meta completely drops off the chart. This disappearance happened because model-specific discussions for their tools fell below our strict threshold of 100 mentions for those years, causing them to be excluded from the final averages. - Missing 2026 Data (xAI and DeepSeek): While Qwen managed to keep up enough volume to log a
+0.35score in 2026, both DeepSeek and xAI do not appear in the 2026 column. This is a direct result of our April 2026 data cutoff. Because we only analyzed the first few months of 2026, there simply wasn't enough time to collect the 100 required samples for those models before the cutoff window closed.
The Sentiment Leaderboard: Top 10 Best-Liked AI Models
To understand which specific implementations hold the highest sustained user affinity, we evaluated the models using a Wilson Score Confidence Interval approach applied to lower-bound sentiment consensus. This math balances raw positive volume against variance, preventing models with low total sample sizes from skewing artificially high.
The resulting leaderboard uncovers a distinct dominance by accessible open-weights systems and highly specialized utility applications:
Top 10 Most Liked AI Models (Wilson Score Sentiment)
Key Observations from the Leaderboard:
- The Open-Weights Edge: Qwen 2.5 and Mistral Nemo Base occupy the top tier. Technical communities routinely reward modularity, zero commercial friction, and local deployment options with highly positive discussions.
- Sustained Commercial Value: Despite heavy general enterprise guardrails, Claude 3.5 Sonnet holds a formidable position at
0.515, largely sustained by developer discussions evaluating it as an industry baseline for real-world code generation and engineering pipelines.
Methodology Notes
- Precision Filtering: By tracking specific model versions and phrases rather than high-level brand names, the dataset purely evaluates user satisfaction with the AI outputs and interfaces themselves.
- Bayesian Smoothed EMA: Online comments change wildly day-to-day. A simple average creates a jagged, unreadable chart. Our Bayesian smoothing uses historical baselines to filter out temporary spikes, meaning the line only moves when a shift is statistically real.
- The Baseline: The dashed green line representing the General Average is critical. It shows that despite individual product wins or failures, the overall industry average stays remarkably steady right around 0.
Conclusion: Product Quality Wins
For AI teams, the lesson is clear: market size doesn't guarantee user love. Launching a massive model like ChatGPT or pushing deep integrations doesn't protect a product if performance drops or updates break user workflows. Long-term loyalty is won by shipping stable, highly optimized tools that just work.